In the videos below you can see HuDOR solve four various tasks
Abstract
Training robots directly from human videos is an emerging area in robotics and computer vision. While there has been notable progress with two-fingered grippers, learning autonomous tasks without teleoperation remains a difficult problem for multi-fingered robot hands. A key reason for this difficulty is that a policy trained on human hands may not directly transfer to a robot hand with a different morphology.
In this work, we present HUDOR, a technique that enables online fine-tuning of the policy by constructing a reward function from the human video. Importantly, this reward function is built using object-oriented rewards derived from off-the-shelf point trackers, which allows for meaningful learning signals even when the robot hand is in the visual observation, while the human hand is used to construct the reward. Given a single video of human solving a task, such as gently opening a music box, HUDOR allows our four- fingered Allegro hand to learn this task with just an hour of online interaction. Our experiments across four tasks, show that HUDOR outperforms alternatives with an average of 4× improvement.
HuDOR generates rewards from human videos by tracking points on the manipulable object, indicated by the rainbow-colored dots, over the trajectory. This allows for online training of multi-fingered robot hands given only a single video of a human solving the task (left) and without robot teleoperation. To optimize the robot's policy (middle), rewards are computed by matching the point movements of the robot policy with those in the human video. In under an hour of online fine-tuning, our Allegro robot hand (right) is able to open the music box.
Policy Rollouts
Music Box Opening
Paper Sliding
Bread Picking
Card Sliding
Generalization to New Objects
Generalization experiments on Bread Picking and Card Sliding task. We input the text prompts on top and bottom as input to the language grounded SAM model to get the initial mask for each object.
Bread Picking Task
Dobby
Brown Music Box
Medicine Bottle
Red Peg
Card Sliding Task
Gum Package
Small Plate
Brown Tissue
Yellow Tea Bag
Generalization to Larger Areas
To generalize to larger areas, we decouple object reaching from object manipulation. We determine the object's location relative to the robot using object detection techniques and relative transforms, apply the same process to the human demonstration, calculate the offset between the current and original object locations, and integrate this offset into the policy trained with HuDOR. For simpler tasks, such as picking up bread, HuDOR achieves an 85% success rate within an evaluation area of 40 cm x 50 cm. However, for more dexterous tasks, the success rate drops to around 40%.
Experiment Results
We ran experiments to answer the following two questions:
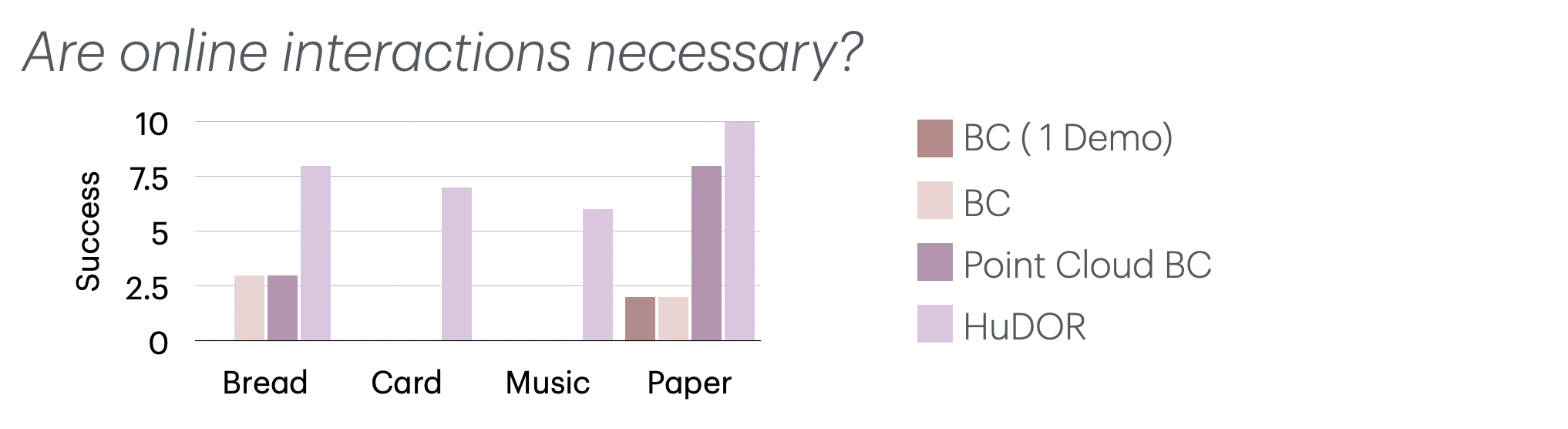
We compared HuDOR to 3 different offline baselines. We ablate the input and the amount of demonstrations used to experiment on different aspects. HuDOR improves upon all of these offline baselines, showcasing the importance of online corrections for better dexterity.
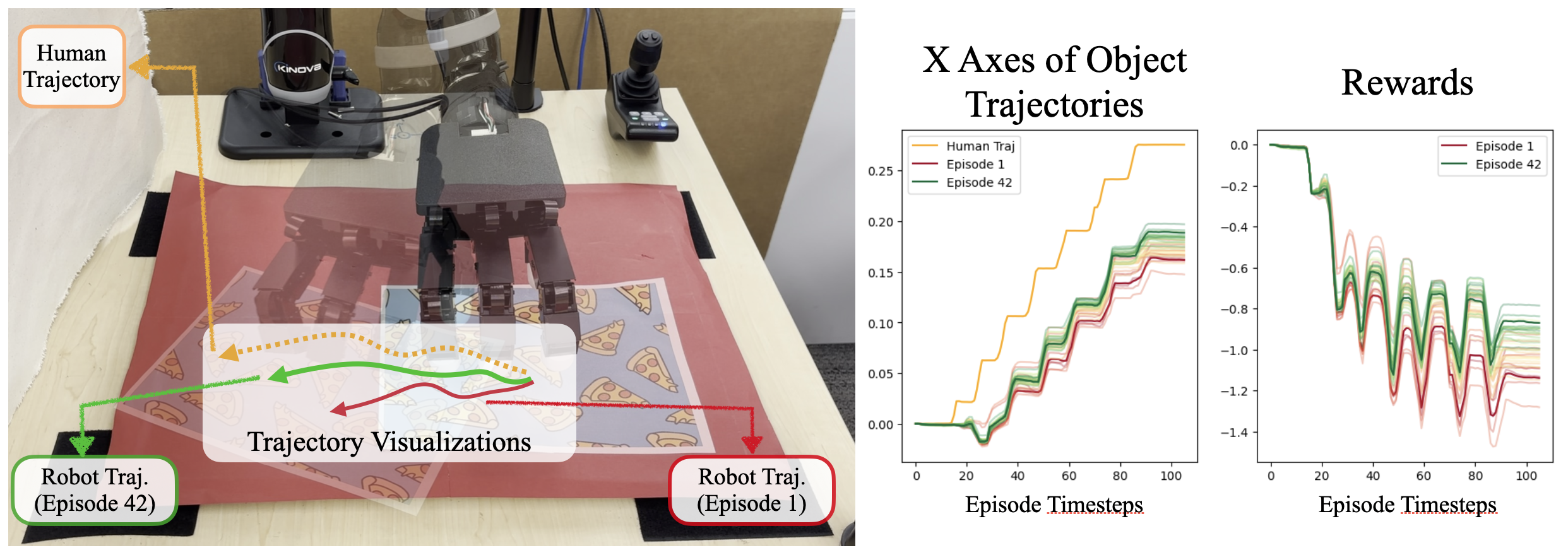
How does the online finetuning improve the policy?
We also illustrate below, how online learning improves the policy in the Paper Sliding task. As can be seen, HuDOR enables the robot policy trajectory to move progressively closer to that of the human expert.
Rollouts of Offline Baselines
We show the rollouts of our best offline baseline Point Cloud BC for three of our tasks below. Note how, in the Bread Picking and Paper Sliding tasks, the hand progressively lowers, while in the Card Sliding task, once the card is slid to the edge, the algorithm fails to recover.
Bread Picking Success
Bread Picking Failure
Card Sliding
Paper Sliding
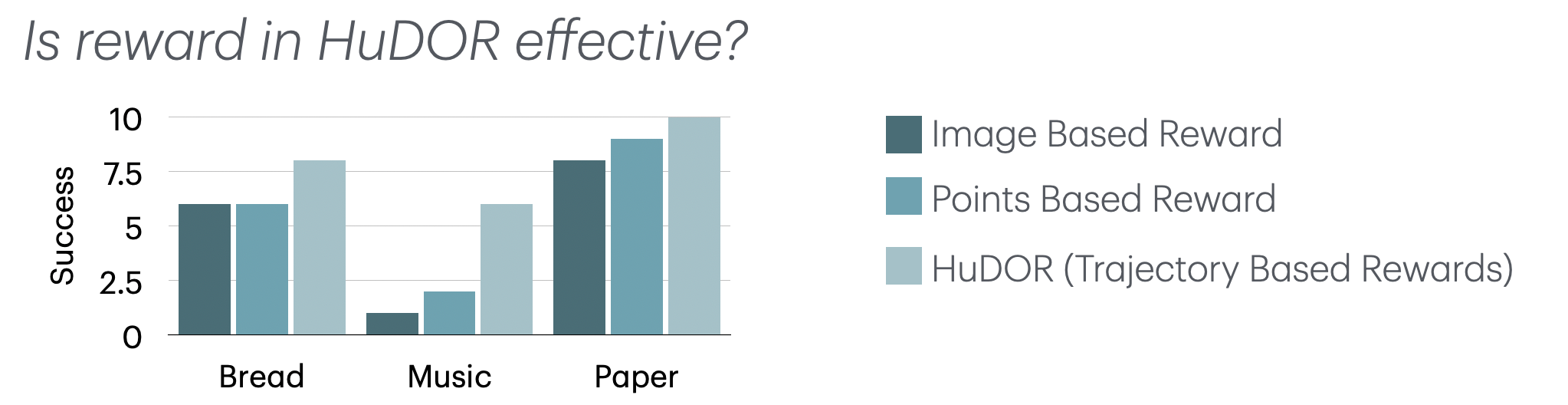
In HuDOR, we use points trajectory based reward functions to guide the online learning. We ablate over our design decision, and train online policies for three of our tasks with image representation based and points based reward functions.
HuDOR shows improvement over both of these baselines.
Example Human Videos
We showcase how the human videos look like. Coupled with the corresponding hand poses, note that this is the only offline data used to train robot policies.